Re-DID Real-life Events Dyadic Interaction Dataset (Re-DID)


 ;
;Re-DID Real-life Events Dyadic Interaction Dataset (Re-DID) |
||
|
|
|
; |






|
Abstract |
This paper proposes a method to detect and localize dyadic human interactions in real videos. The idea stems from the significant difference between an action performed by a single subject and an interaction between two persons. In the first case all the visual information is concentrated on the subject, while in the latter case the action of a person is related to the interacting person's attitude, following an action/reaction principle. This kind of behavior is significant especially in natural and real scenarios, in which people are moving freely without the awareness of being recorded. To highlight these features and provide researchers with a common ground for comparisons, we have collected and annotated a new dataset, retrieving from YouTube 30 different videos of a specific type of interaction, namely urban fight situations. The proposed dataset is one of the most challenging annotated video collection concerning dyadic interactions, due to the intrinsic intra-class variability characterizing real fights. In addition, we provide an extensive experimental analysis on this dataset and we demonstrate that the visual information extracted in the area associated to the interpersonal space plays a fundamental role in detecting fights. |
Data Description |
|||
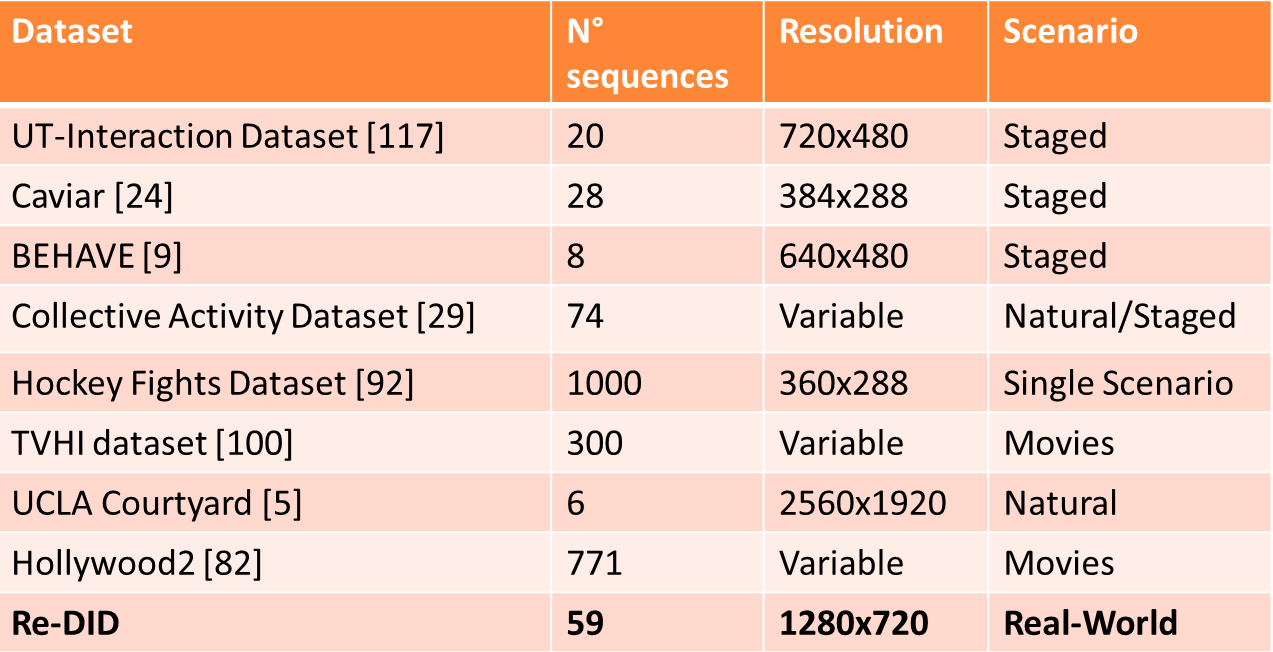
All the videos in the dataset are retrieved from YouTube; 25 of them are recorded using car mounted Dash-Cams, the remaining ones have been taken by other devices such as mobile phones. The length of the videos varies from 0:20 to 4:02 (mm:ss) and the resolution has been normalized to 1280x720 for the sake of homogeneity. The dataset includes 73 different fight instances under different lighting (day, night) and weather conditions (sunny, rainy), different original video resolution (native 1280x720, upsampled videos), different camera views (wide angle, fish-eye, zoomed view), moving and static scenes. The dataset has annotations of the position of the subjects' bounding boxes for each frame and relative ID, the temporal window where the interaction occurs, and the position of the interpersonal spaces (see paper cited below) precomputed for the ground truth. For what concerns the interaction triggering and ending, we have considered a general rule for the annotation process, starting with the first contact between the involved subjects until a relevant distancing is takes place. |
Datasets Comparison |
|
Annotations |
||||||
| Person's BBoxes | ||||||
| frame number | X top-left corner | Y top-left corner | width | height | object's type | ID |
| 6 | 153 | 9 | 141 | 99 | person | 1 |
| Action's BBoxes | ||||||
| starting frame number | ending frame number | ID1 | action | ID2 | ||
| 525 | 670 | 0 | fight | 2 | ||
| Interpersonal space's BBoxes | ||||||
| frame number | X top-left corner | Y top-left corner | width | height | ID1 | ID2 |
| 203 | 365 | 57 | 60 | 60 | 0 | 1 |
Visual Features |
| Visual features are in binary format where each value is in single precision and each trajectory is composed as follows: |
| - 10 [header (frame, mean_x, mean_y, var_x, var_y, length, scale, x_pos, y_pos, t_pos)] |
| - 30+30 [trajectory position + trajectory normalized (x,y, 15 frames long)] |
| - 96 [HOG descriptor (8x2x2x3)] |
| - 108 [HOF descriptor (9x2x2x3)] |
| - 96 [MBH descriptor X(8x2x2x3)] |
| - 96 [MBH descriptor Y(8x2x2x3)] |
Reference |
| You can download the paper here Please cite this: |
||
|
@INPROCEEDINGS{rota2015real, |
Download files |
| Original (1280x720) | |
| Videos | Actions' BBoxes |
| Person's BBoxes | Interpersonal space BBoxes |
| Visual Features | |
| Reduced (340x360) | |
| Videos | Actions' BBoxes |
| Person's BBoxes | Interpersonal space BBoxes |
| Visual Features | |
Contacts |
|
For further details please contact: | ||